

रोबोट क्या है.txt?
रोबोट.txt एक फ़ाइल है जो खोज इंजन को बताती है कि किन पृष्ठों को क्रॉल करना है और किन से बचना है। यह क्रॉलर को उन पृष्ठों पर मार्गदर्शन करने के लिए "अनुमति दें" और "अनुमति" दोनों निर्देशों का उपयोग करता है जिन्हें आप अनुक्रमित करना चाहते हैं।
आपकी वेबसाइट को खोज परिणामों में रैंक करने के लिए, Google को उसे क्रॉल और इंडेक्स करने की आवश्यकता होती है. यह प्रक्रिया Google को आपकी वेबसाइट पर सामग्री की खोज करने, यह समझने में सक्षम बनाती है कि पृष्ठ पर क्या है, और अपने पृष्ठों को उपयुक्त खोज परिणामों में दिखा सकता है।
Google को अपने पृष्ठों को क्रॉल करने में मदद करने के लिए, आपको रोबोट.txt फ़ाइल का उपयोग करना होगा. इस पृष्ठ पर, हम रोबोट.txt फ़ाइलों के बारे में आपके सभी ज्वलंत सवालों के जवाब देंगे, जिनमें शामिल हैं:
- रोबोट क्या है.txt?
- Robots.txt फ़ाइल एनाटॉमी
- रोबोट्स.txt कहां से आया?
- रोबोट.txt उदाहरण
- रोबोट क्यों महत्वपूर्ण हैं.txt महत्वपूर्ण है?
- Robots.txt फ़ाइल कैसे बनाएँ
- रोबोट.txt फ़ाइलों के साथ सामान्य समस्याएं
- आपको रोबोट की फ़ाइल कब अपडेट .txt चाहिए?
- सफलतापूर्वक एसईओ के लिए.txt रोबोट करने के लिए 6 युक्तियाँ
Robots.txt फ़ाइल एनाटॉमी
इस एनाटॉमी विश्लेषण के साथ robots.txt के बारे में अधिक जानें:
| अवयव | लक्ष्य | उदाहरण |
| उपयोगकर्ता एजेंट | यह निर्धारित करता है कि नियम किस पर लागू होता है, जैसे सभी या विशिष्ट क्रॉलर | उपयोगकर्ता-एजेंट: Googlebot |
| अनुमति न दें | परिभाषित करता है कि उपयोगकर्ता एजेंट को कौन से फ़ोल्डर क्रॉल नहीं करने चाहिए | अस्वीकृत करें: /गोपनीय/ |
| अनुमति दें | परिभाषित करता है कि उपयोगकर्ता एजेंट को अस्वीकृत फ़ोल्डरों में कौन से फ़ोल्डर क्रॉल करने चाहिए | अनुमति दें: /confidential/public-report.pdf |
| टिप्पणियाँ | दर्शकों के लिए नियम क्या हैं, यह परिभाषित करता है | # Googlebot को public-report.pdf को छोड़कर /confidential/ को क्रॉल करने से रोकता है |
| साइट मैप | XML साइटमैप कहाँ रहेगा यह परिभाषित करता है | साइटमैप: https://example.com/sitemap.xml |
robots.txt कहां से आया?
1994 में, robots.txt फ़ाइल को RobotsNotWanted.txt के नाम से जाना जाता था (यह नाम वेब क्रॉलर द्वारा सर्वर पर अधिक भार डालने के कारण दिया गया था), जिसका साझा लक्ष्य वेबमास्टरों को क्रॉलरों को यह बताने की क्षमता प्रदान करना था कि उन्हें क्या क्रॉल नहीं करना है ।
नाम (RobotsNotWanted.txt) टिक नहीं पाया।
उसी वर्ष प्रोटोकॉल का नाम बदलकर robots.txt कर दिया गया और इसे उस समय के सर्च इंजन जैसे कि अल्टाविस्टा द्वारा अपनाया गया। दो दशक से भी अधिक समय बाद, Google ने इंटरनेट इंजीनियरिंग टास्क फोर्स (IETF) के माध्यम से robots.txt के प्रबंधन को औपचारिक रूप दिया।
IETF robots.txt के मानकीकरण पर ध्यान केंद्रित करता है:
- नामकरण, जैसे फ़ाइल को “robots.txt” कहना
- कार्यान्वयन, जैसे फ़ाइल को रूट फ़ोल्डर पर रखना
- एन्कोडिंग, जैसे UTF-8 का उपयोग करना
- संरचना, जैसे समूह और नियम होना
यह ध्यान देने योग्य है कि Google ने robots.txt प्रबंधन को औपचारिक रूप देने की शुरुआत की, लेकिन प्रोटोकॉल का स्वामित्व उसके पास नहीं है। IETF एक गैर-लाभकारी संगठन है (और एक अन्य गैर-लाभकारी संगठन, इंटरनेट सोसाइटी का एक हिस्सा) जो Google और इसकी मूल कंपनी, अल्फाबेट से अलग है।
रोबोट.txt उदाहरण
तो, रोबोट .txt फ़ाइल कैसी दिखती है? प्रत्येक रोबोट .txt फ़ाइल इस बात पर निर्भर करती है कि आप क्या करते हैं और Google को क्रॉल करने की अनुमति नहीं देते हैं।
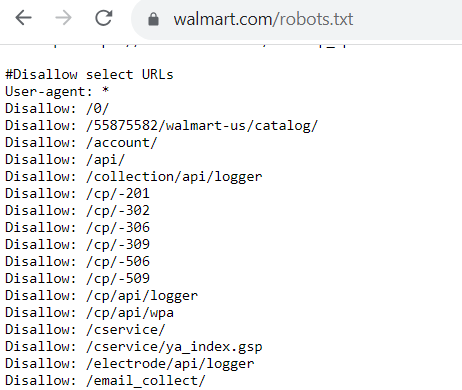
यदि ऐसे पृष्ठ हैं जो आप बॉट्स को क्रॉल करने की अनुमति देते हैं, तो कोड इस तरह दिखेगा:
User-agent: Googlebot
Allow: /
उपयोगकर्ता-एजेंट वह बॉट है जिसे आप अपनी वेबसाइट को क्रॉल करने की अनुमति देते हैं (या अनुमति नहीं देते हैं)। इस रोबोट में.txt उदाहरण के लिए, आप Googlebot को अपनी वेबसाइट पर पृष्ठों को क्रॉल करने की अनुमति दे रहे हैं।
अब, यदि आप नहीं चाहते हैं कि बॉट आपकी वेबसाइट पर पृष्ठों को क्रॉल करे, तो कोड इस तरह दिखता है:
User-agent: Bingbot
Disallow: /
इस रोबोट के लिए.txt उदाहरण के लिए, यह कोड इंगित करता है कि बिंगबोट किसी वेबसाइट पर पृष्ठों को क्रॉल नहीं कर सकता है।
रोबोट .txt महत्वपूर्ण क्यों है?
तो, रोबोट .txt क्यों मायने रखता है? आपको इस फ़ाइल को अपनी वेबसाइट में एकीकृत करने के बारे में चिंता करने की आवश्यकता क्यों है?
यहां कुछ कारण दिए गए हैं कि रोबोट.txt आपकी खोज इंजन अनुकूलन (एसईओ) रणनीति के लिए महत्वपूर्ण है:
1. यह आपकी वेबसाइट को ओवरलोड होने से बचाता है
रोबोट की फ़ाइल को लागू करने के सबसे बड़े कारणों में से एक आपकी वेबसाइट को क्रॉल अनुरोधों से ओवरलोड होने से रोकना .txt है।
रोबोट .txt फ़ाइल के साथ, आप अपनी वेबसाइट पर क्रॉल ट्रैफ़िक को प्रबंधित करने में मदद करते हैं ताकि यह आपकी वेबसाइट को अभिभूत और धीमा न करे।
Google आपकी वेबसाइट पर क्रॉल और इंडेक्स पृष्ठों को क्रॉल अनुरोध भेजेगा - यह एक बार में दर्जनों अनुरोध भेज सकता है। रोबोट .txt फ़ाइल के साथ, आप अपनी वेबसाइट पर क्रॉल ट्रैफ़िक को प्रबंधित करने में मदद करते हैं ताकि यह आपकी वेबसाइट को अभिभूत और धीमा न करे।
एक धीमी वेबसाइट के एसईओ के लिए नकारात्मक परिणाम होते हैं, क्योंकि Google खोज परिणामों में तेजी से लोड होने वाली वेबसाइटों को वितरित करना चाहता है। इसलिए, रोबोट .txt फ़ाइल को लागू करके, आप यह सुनिश्चित करते हैं कि Google आपकी वेबसाइट को क्रॉल करते समय ओवरलोड और धीमा न करे।
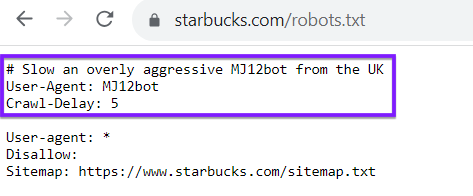
ध्यान रखें, आपकी रोबोट .txt फ़ाइल Google या Bing जैसे खोज इंजन क्रॉलर के लिए अनन्य नहीं है। आप अन्य वेबसाइटों से क्रॉलर को निर्देशित करने के लिए अपनी रोबोट .txt फ़ाइल का भी उपयोग कर सकते हैं। एक उदाहरण के रूप में, स्टारबक्स के लिए रोबोट .txt फ़ाइल देखें, जो एक निश्चित बॉट में देरी करता है:
2. यह आपको अपने क्रॉल बजट को अनुकूलित करने में मदद करता है
प्रत्येक वेबसाइट का एक क्रॉल बजट होता है, जो Google द्वारा एक विशिष्ट समय के भीतर क्रॉल किए जाने वाले पृष्ठों की संख्या है। यदि आपकी वेबसाइट पर आपके क्रॉल बजट की तुलना में अधिक पृष्ठ हैं, तो इससे पृष्ठ अनुक्रमित नहीं होते हैं, जिसका अर्थ है कि वे रैंक नहीं कर सकते हैं।
जबकि आपकी रोबोट .txt फ़ाइल पृष्ठों को अनुक्रमित होने से नहीं रोक सकती है, यह क्रॉलर को निर्देशित कर सकती है कि उन्हें अपना समय कहां बिताना है।
रोबोट का उपयोग करना.txt आपको अपने क्रॉल बजट को अनुकूलित करने में मदद करता है। यह Google बॉट्स को उन पृष्ठों की ओर मार्गदर्शन करने में मदद करता है जिन्हें आप अनुक्रमित करना चाहते हैं. जबकि आपकी रोबोट .txt फ़ाइल पृष्ठों को अनुक्रमित होने से नहीं रोक सकती है, यह क्रॉल बॉट्स को उन पृष्ठों पर केंद्रित रख सकती है जिन्हें सबसे अधिक अनुक्रमित करने की आवश्यकता है।
3. यह क्रॉलर को गैर-सार्वजनिक पृष्ठों को क्रॉल करने से रोकने में मदद करता है
प्रत्येक कंपनी की वेबसाइट पर ऐसे पृष्ठ होते हैं जिन्हें वे खोज परिणामों में प्रदर्शित नहीं करना चाहते हैं, जैसे लॉगिन और डुप्लिकेट पेज। रोबोट.txt इन पृष्ठों को खोज परिणामों में रैंकिंग से रखने में मदद कर सकते हैं और पृष्ठों को क्रॉलर से ब्लॉक कर सकते हैं।
robots.txt फ़ाइल कैसे बनाएँ
अपनी robots.txt फ़ाइल बनाने के लिए इन चरणों का पालन करें:
- नोटपैड (विंडोज) या टेक्स्टएडिट (मैक) जैसे टेक्स्ट एडिटर में नई फ़ाइल बनाएं
- अपने नियमों को परिभाषित करें, उन्हें समूहों और निर्देशों के रूप में व्यवस्थित करें
- अपने नियमों को अन्य दर्शकों, जैसे टीम के साथियों, को टिप्पणियों के माध्यम से समझाएँ
- अपनी फ़ाइल के अंत में अपना XML साइटमैप स्थान जोड़ें
- अपनी फ़ाइल को robots.txt के रूप में सहेजें
- अपनी robots.txt फ़ाइल को अपनी साइट के रूट फ़ोल्डर में अपलोड करें
- Google Search Console और Bing Webmaster Tools में अपने robots.txt फ़ाइल नियमों का परीक्षण करें
रोबोट.txt फ़ाइलों के साथ सामान्य समस्याएँ
कभी-कभी, रोबोट का उपयोग करते समय वेबसाइटें समस्याओं का अनुभव करती हैं.txt। एक संभावित समस्या यह है कि फ़ाइल Google (या अन्य खोज इंजन) को आपकी वेबसाइट को क्रॉल करने से रोकती है। यदि आपको लगता है कि ऐसा कुछ हो रहा है, तो आप इसे ठीक करने के लिए अपनी रोबोट .txt फ़ाइल को अपडेट करना चाहेंगे।
एक और संभावित समस्या यह है कि आपकी साइट पर कहीं भी संवेदनशील या निजी डेटा है (या तो आपके व्यवसाय या आपके ग्राहकों के लिए निजी), और रोबोट .txt फ़ाइल इसे अवरुद्ध नहीं करती है, जिससे Google उस डेटा को स्वतंत्र रूप से क्रॉल कर सकता है। यह एक बहुत बड़ा उल्लंघन है, इसलिए आपको यह सुनिश्चित करने की आवश्यकता है कि आप क्रॉलर से उस डेटा को ब्लॉक करें।
आपको रोबोट .txt फ़ाइल कब अपडेट करनी चाहिए?
रोबोट की फ़ाइल बनाने के बाद भी, आपको इसे किसी बिंदु पर अपडेट करने .txt आवश्यकता होगी। लेकिन आपको ऐसा करने की आवश्यकता कब हो सकती है, बिल्कुल?
यहां कुछ समय दिए गए हैं जब आप अपने रोबोट .txt फ़ाइल को अपडेट कर सकते हैं:
- जब आप किसी नए सामग्री प्रबंधन सिस्टम (CMS) पर माइग्रेट करते हैं
- जब आप सुधारना चाहते हैं कि Google आपकी साइट को कैसे क्रॉल करता है
- जब आप अपनी साइट पर कोई नया अनुभाग या उपडोमेन जोड़ते हैं
- जब आप पूरी तरह से एक नई वेबसाइट में बदल जाते हैं
इन सभी परिवर्तनों के लिए आपको अपनी साइट पर क्या हो रहा है.txt प्रतिबिंबित करने के लिए अपनी रोबोट की फ़ाइल को अंदर जाने और संपादित करने की आवश्यकता होती है।
रोबोट करने के लिए 6 युक्तियाँ.txt एसईओ के लिए सफलतापूर्वक
अपनी वेबसाइट में रोबोट.txt फ़ाइल को लागू करने के लिए तैयार हैं? इसे सफलतापूर्वक करने में आपकी सहायता करने के लिए यहां 6 युक्तियां दी गई हैं:
- Make Sure All Your Important Pages Are Crawlable
- Only Use Each User-agent Once
- Use New Lines for Each Directive
- Make Sure You Use Proper Use Cases
- Use the “*” Symbol to Give Direction
- Use the “$” to Simplify Coding
1. सुनिश्चित करें कि आपके सभी महत्वपूर्ण पृष्ठ क्रॉल करने योग्य हैं
अपनी रोबोट .txt फ़ाइल बनाने से पहले, अपनी वेबसाइट पर सबसे महत्वपूर्ण पृष्ठों की पहचान करना महत्वपूर्ण है। आप यह सुनिश्चित करना चाहते हैं कि वे पृष्ठ क्रॉल हो जाएं, ताकि वे खोज परिणामों में रैंक कर सकें।
अपनी रोबोट .txt फ़ाइल बनाने से पहले, उन महत्वपूर्ण पृष्ठों को दस्तावेज़ करें जिन्हें आप खोज बॉट्स को क्रॉल करने की अनुमति देना चाहते हैं। इनमें आपके जैसे पृष्ठ शामिल हो सकते हैं:
- उत्पाद पृष्ठ
- हमारे बारे में पृष्ठ
- सूचनात्मक पृष्ठ
- ब्लॉग पोस्ट
- संपर्क पृष्ठ
2. केवल एक बार प्रत्येक उपयोगकर्ता-एजेंट का उपयोग करें
जब आप अपनी रोबोट .txt फ़ाइल बनाते हैं, तो यह महत्वपूर्ण है कि प्रत्येक उपयोगकर्ता-एजेंट का उपयोग केवल एक बार किया जाए। इसे इस तरह से करने से आपके कोड को साफ और व्यवस्थित रखने में मदद मिलती है, खासकर यदि कुछ पृष्ठ हैं जिन्हें आप अस्वीकार करना चाहते हैं।
यहां एक रोबोट है.txt उदाहरण अंतर दिखा रहा है:
User-agent: Googlebot
Disallow: /pageurl
User-agent: Googlebot
Disallow: /loginpage
अब, कल्पना करें कि आपको कई यूआरएल के लिए ऐसा करने की आवश्यकता है। यह दोहराव हो जाएगा और आपके रोबोट की फ़ाइल .txt पालन करना मुश्किल हो जाएगा। इसके बजाय, इसे इस तरह से व्यवस्थित करना सबसे अच्छा है:
User-agent: Googlebot
Disallow: /pageurl/
Disallow: /loginpage/
इस सेटअप के साथ, सभी अस्वीकृत लिंक विशिष्ट उपयोगकर्ता-एजेंट के तहत व्यवस्थित किए जाते हैं। यह संगठित दृष्टिकोण आपके लिए विशिष्ट बॉट्स के लिए समायोजित करने, जोड़ने या हटाने के लिए आवश्यक लाइनों को ढूंढना आसान बनाता है।
3. प्रत्येक निर्देश के लिए नई लाइनों का उपयोग करें
जब आप अपनी रोबोट .txt फ़ाइल बनाते हैं, तो यह महत्वपूर्ण है कि आप प्रत्येक निर्देश को अपनी लाइन पर रखें। फिर, यह टिप आपके लिए अपनी फ़ाइल को प्रबंधित करना आसान बना देगी।
इसलिए, जब भी आप एक उपयोगकर्ता एजेंट जोड़ते हैं, तो यह बॉट नाम के साथ अपनी लाइन पर होना चाहिए। अगली पंक्ति में अस्वीकृत या अनुमति जानकारी होनी चाहिए। हर बाद की अस्वीकृत लाइन अपने आप होनी चाहिए।
यहां एक रोबोट है.txt उदाहरण है कि क्या नहीं करना है:
User-agent: Googlebot Disallow: /pageurl/ Disallow: /loginpage/
जैसा कि आप देख सकते हैं, यह आपके रोबोट को पढ़ना अधिक चुनौतीपूर्ण बनाता है.txt और जानें कि यह क्या कहता है।
यदि आप कोई गलती करते हैं, उदाहरण के लिए, ठीक करने के लिए सही लाइन ढूंढना मुश्किल होगा।
प्रत्येक निर्देश को अपनी लाइन पर रखने से बाद में बदलाव करना आसान हो जाएगा।
4. सुनिश्चित करें कि आप उचित उपयोग के मामलों का उपयोग करते हैं
यदि एसईओ के लिए रोबोट के बारे में जानने के लिए एक बात है.txt तो यह है कि यह फ़ाइल केस-संवेदनशील है। आपको यह सुनिश्चित करने की आवश्यकता है कि आप उचित उपयोग के मामलों का उपयोग करें, ताकि यह आपकी वेबसाइट पर सही ढंग से काम करे।
सबसे पहले, आपकी फ़ाइल को उस उपयोग मामले में "रोबोट.txt" के रूप में लेबल करने की आवश्यकता है।
दूसरा, आपको URL के किसी भी पूंजीकरण भिन्नताओं के लिए खाता बनाना होगा। यदि आपके पास एक यूआरएल है जो सभी कैप्स का उपयोग करता है, तो आपको इसे अपने रोबोट की फ़ाइल में इनपुट करना होगा.txt जैसे।
5. दिशा देने के लिए "*" प्रतीक का उपयोग करें
यदि आपके पास एक ही पते के तहत कई URL हैं जिन्हें आप बॉट्स को क्रॉल करने से रोकना चाहते हैं, तो आप उन सभी URL को एक बार में ब्लॉक करने के लिए "*" प्रतीक का उपयोग कर सकते हैं, जिसे वाइल्डकार्ड कहा जाता है।
उदाहरण के लिए, मान लें कि आप आंतरिक खोजों से संबंधित सभी पृष्ठों को अस्वीकार करना चाहते हैं। प्रत्येक पृष्ठ को व्यक्तिगत रूप से अवरुद्ध करने के बजाय, आप अपनी फ़ाइल को सरल बना सकते हैं।
इसे इस तरह दिखने के बजाय:
User-agent: *
Disallow: /search/hoodies/
Disallow: /search/red-hoodies/
Disallow: /search/sweaters
आप इसे सरल बनाने के लिए "*" प्रतीक का उपयोग कर सकते हैं:
User-agent: *
Disallow: /search/*
इस चरण को लागू करके, खोज इंजन बॉट्स को "खोज" सबफ़ोल्डर के तहत किसी भी URL को क्रॉल करने से अवरुद्ध कर दिया जाता है। वाइल्डकार्ड प्रतीक का उपयोग करना आपके लिए बैचों में पृष्ठों को अस्वीकार करने का एक आसान तरीका है।
6. कोडिंग को सरल बनाने के लिए "$" का उपयोग करें
कई कोडिंग ट्रिक्स हैं जिनका उपयोग आप अपने रोबोट की फ़ाइल बनाने में आसान बनाने .txt लिए कर सकते हैं। एक चाल यूआरएल के अंत को इंगित करने के लिए "$" प्रतीक का उपयोग करना है।
यदि आपके पास समान पृष्ठ हैं जिन्हें आप अस्वीकार करना चाहते हैं, तो आप इसे सभी समान URL पर लागू करने के लिए "$" का उपयोग करके अपना समय बचा सकते हैं।
उदाहरण के लिए, मान लें कि आप Google को अपने वीडियो क्रॉल करने से रोकना चाहते हैं. यहां बताया गया है कि यदि आप प्रत्येक को करते हैं तो यह कोड कैसा दिख सकता है:
User-agent: Googlebot
Disallow: /products.3gp
Disallow: /sweaters.3gp
Disallow: /hoodies.3gp
उन सभी को अलग-अलग लाइनों पर रखने के बजाय, आप उन सभी को अस्वीकार करने के लिए "$" का उपयोग कर सकते हैं। यह इस तरह दिखता है:
User-agent: GooglebotDisallow: /*.3gp$
इस प्रतीक का उपयोग क्रॉलर को इंगित करता है कि ".3gp" के साथ समाप्त होने वाले किसी भी पृष्ठ को क्रॉल नहीं किया जा सकता है।
अपने एसईओ ज्ञान को विस्तृत करें
अपनी वेबसाइट पर रोबोट जोड़ना.txt Google को आपके पृष्ठों को ओवरलोड किए बिना क्रॉल करने में मदद करने के लिए महत्वपूर्ण है। यह उन पहलुओं में से एक है जो आपको एसईओ को प्रभावी ढंग से करने में मदद करेंगे।
क्या आप अपनी साइट के SEO को बेहतर बनाना चाहते हैं? हमारी विशेषज्ञ टीम आपको प्रभावी robots.txt रणनीतियों को लागू करने और बेहतर इंडेक्सिंग के लिए आपकी वेबसाइट को अनुकूलित करने में मदद कर सकती है। आज ही हमसे ऑनलाइन संपर्क करें और जानें कि हम आपकी SEO पहलों का समर्थन कैसे कर सकते हैं!
एसईओ सेवाएँ जो कुकी कटर नहीं हैं
अपने व्यवसाय, उद्योग और राजस्व लक्ष्यों के अनुरूप SEO रणनीति प्राप्त करें।


एसईओ सेवाएँ जो कुकी कटर नहीं हैं
अपने व्यवसाय, उद्योग और राजस्व लक्ष्यों के अनुरूप SEO रणनीति प्राप्त करें।
लेखकों
