

O que é o robots.txt?
Robots.txt é um ficheiro que indica aos motores de busca quais as páginas que devem ser rastreadas e quais as que devem ser evitadas. Utiliza instruções de "permitir" e "não permitir" para orientar os rastreadores para as páginas que pretende indexar.
Para que o seu Web site seja classificado nos resultados de pesquisa, o Google precisa de o rastrear e indexar. Este processo permite ao Google descobrir o conteúdo do seu sítio Web, compreender o que está na página e mostrar as suas páginas nos resultados de pesquisa adequados.
Para ajudar o Google a rastrear as suas páginas, é necessário utilizar um ficheiro robots.txt. Nesta página, responderemos a todas as suas perguntas sobre os ficheiros robots.txt, incluindo:
- O que é Robots.txt?
- Anatomia do ficheiro Robots.txt
- De onde veio o Robots.txt?
- Exemplo de Robots.txt
- Porque é que o Robots.txt é importante?
- Como criar um ficheiro Robots.txt
- Problemas comuns com ficheiros Robots.txt
- Quando deve atualizar um ficheiro Robots.txt?
- 6 dicas para fazer o Robots.txt para SEO com sucesso
Anatomia do ficheiro Robots.txt
Saiba mais sobre o robots.txt com esta análise anatómica:
| Componente | Objetivo | Exemplo |
| Agente do utilizador | Define a quem é que a regra se aplica, como a todos os crawlers ou a crawlers específicos | Agente do utilizador: Googlebot |
| Não permitir | Define as pastas que o agente do utilizador não deve rastrear | Não permitir: /confidential/ |
| Permitir | Define quais as pastas que o agente do utilizador deve rastrear dentro das pastas não permitidas | Permitir: /confidential/public-report.pdf |
| Comentários | Define as regras para os telespectadores | # Bloqueia o Googlebot de rastrear /confidential/ exceto para public-report.pdf |
| Mapa do site | Define o local onde se encontra o mapa do sítio XML | Mapa do sítio: https://example.com/sitemap.xml |
De onde veio o robots.txt?
Em 1994, o ficheiro robots.txt era conhecido como RobotsNotWanted.txt (nome dado em resposta a um web crawler que sobrecarregava um servidor), com o objetivo comum de dar aos webmasters a capacidade de dizer aos crawlers o que não deviam rastrear.
O nome (RobotsNotWanted.txt) não pegou.
O protocolo foi renomeado para robots.txt no mesmo ano e foi adotado pelos motores de pesquisa da época, como o AltaVista. Mais de duas décadas depois, a Google formalizou a gestão do robots.txt através da Internet Engineering Task Force (IETF).
A IETF centra-se na normalização dos robots.txt:
- Nomeação, como chamar ao ficheiro "robots.txt"
- Implementação, como colocar o ficheiro na pasta de raiz
- Codificação, como utilizar UTF-8
- Estrutura, como ter grupos e regras
Vale a pena mencionar que, embora o Google tenha iniciado a formalização do gerenciamento do robots.txt, ele não é proprietário do protocolo. A IETF é uma organização sem fins lucrativos (e filha de outra organização sem fins lucrativos, a Internet Society) separada da Google e da sua empresa-mãe, a Alphabet.
Exemplo de Robots.txt
Então, qual é o aspeto de um ficheiro robots.txt? Cada ficheiro robots.txt tem um aspeto diferente, dependendo do que permite ou não que o Google rastreie.
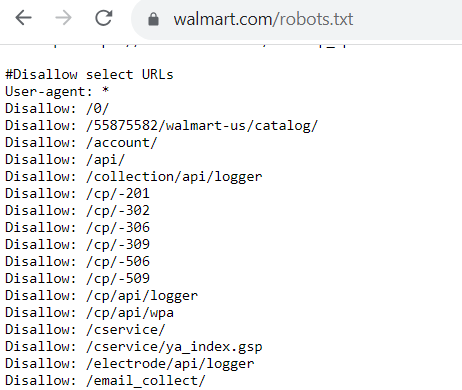
Se houver páginas que permite que os bots rastreiem, o código terá o seguinte aspeto:
User-agent: Googlebot
Allow: /
O user-agent é o bot que permite (ou não permite) que o seu sítio Web seja rastreado. Neste exemplo de robots.txt, está a permitir que o Googlebot rastreie as páginas do seu sítio Web.
Agora, se não quiser que um bot rastreie as páginas do seu sítio Web, o código tem o seguinte aspeto:
User-agent: Bingbot
Disallow: /
Para este exemplo de robots.txt, este código indica que o Bingbot não pode rastrear páginas num sítio Web.
Porque é que o robots.txt é importante?
Então, porque é que o robots.txt é importante? Porque é que tem de se preocupar com a integração deste ficheiro no seu Web site?
Eis algumas razões pelas quais o robots.txt é crucial para a sua estratégia de otimização dos motores de busca (SEO):
1. Evita que o seu sítio Web fique sobrecarregado
Uma das principais razões para implementar um ficheiro robots.txt é evitar que o seu Web site fique sobrecarregado com pedidos de rastreio.
Com o ficheiro robots.txt implementado, ajuda a gerir o tráfego de rastreio no seu sítio Web, de modo a não sobrecarregar e tornar o seu sítio Web mais lento.
O Google enviará pedidos de rastreio para rastrear e indexar páginas no seu Web site - pode enviar dezenas de pedidos de uma só vez. Com o ficheiro robots.txt implementado, ajuda a gerir o tráfego de rastreio no seu sítio Web, para que não o sobrecarregue e torne o seu sítio Web mais lento.
Um sítio Web lento tem consequências negativas para a SEO, uma vez que o Google pretende apresentar sítios Web de carregamento rápido nos resultados de pesquisa. Assim, ao implementar o ficheiro robots.txt, garante que o Google não sobrecarrega nem torna o seu sítio Web mais lento enquanto o rastreia.
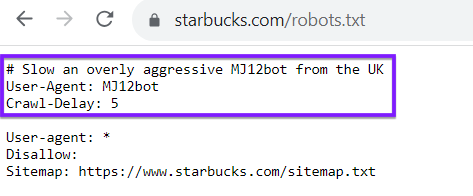
Tenha em atenção que o seu ficheiro robots.txt não é exclusivo dos rastreadores dos motores de busca, como o Google ou o Bing. Também pode utilizar o seu ficheiro robots.txt para direcionar os crawlers de outros sítios Web. Por exemplo, veja o ficheiro robots.txt do Starbucks, que atrasa um determinado bot:
2. Ajuda-o a otimizar o seu orçamento de rastreio
Todos os sítios Web têm um "crawl budget", que é o número de páginas que o Google rastreia num determinado período de tempo. Se o seu sítio Web tiver mais páginas do que as permitidas no seu crawl budget, as páginas não serão indexadas, o que significa que não podem ser classificadas.
Embora o ficheiro robots.txt não possa impedir que as páginas sejam indexadas, pode orientar os rastreadores sobre onde gastar o seu tempo.
A utilização do robots.txt ajuda-o a otimizar o seu orçamento de rastreio. Ajuda a orientar os bots do Google para as páginas que pretende indexar. Embora o seu ficheiro robots.txt não possa impedir que as páginas sejam indexadas, pode manter os bots de rastreio concentrados nas páginas que mais precisam de ser indexadas.
3. Ajuda a impedir que os crawlers rastreiem páginas não públicas
Todas as empresas têm páginas no seu sítio Web que não querem que apareçam nos resultados de pesquisa, como páginas de início de sessão e páginas duplicadas. O ficheiro Robots.txt pode ajudar a impedir que estas páginas sejam classificadas nos resultados de pesquisa e bloqueia as páginas dos crawlers.
Como criar um ficheiro robots.txt
Siga estes passos para criar o seu ficheiro robots.txt:
- Criar um novo ficheiro num editor de texto como o Notepad (Windows) ou o TextEdit (Mac)
- Defina as suas regras, organizadas como grupos e diretivas
- Explicar as suas regras a outros espectadores, como colegas de equipa, com comentários
- Adicione a localização do seu mapa do site XML no final do seu ficheiro
- Guarde o seu ficheiro como robots.txt
- Carregue o seu ficheiro robots.txt para a pasta de raiz do seu sítio
- Teste as regras do seu ficheiro robots.txt na Consola de Pesquisa do Google e nas Ferramentas do Google para webmasters do Bing
Problemas comuns com ficheiros robots.txt
Por vezes, os sítios Web têm problemas quando utilizam o ficheiro robots.txt. Um problema potencial é o facto de o ficheiro impedir o Google (ou outros motores de busca) de rastrear o seu Web site. Se isso estiver a acontecer, deve atualizar o seu ficheiro robots.txt para corrigir o problema.
Outro problema potencial é que existem dados confidenciais ou privados algures no seu site (privados para a sua empresa ou para os seus clientes) e o ficheiro robots.txt não os bloqueia, permitindo que o Google rastreie livremente esses dados. Isso é uma grande violação, por isso é necessário certificar-se de que bloqueia esses dados dos rastreadores.
Quando é que se deve atualizar um ficheiro robots.txt?
Mesmo depois de criar um ficheiro robots.txt, é provável que tenha de o atualizar em algum momento. Mas quando é que precisa de fazer isso, exatamente?
Eis algumas ocasiões em que pode atualizar o seu ficheiro robots.txt:
- Quando se migra para um novo sistema de gestão de conteúdos (CMS)
- Quando pretende melhorar a forma como o Google rastreia o seu sítio
- Quando adiciona uma nova secção ou subdomínio ao seu site
- Quando se muda para um novo sítio Web
Todas estas alterações exigem que edite o seu ficheiro robots.txt para refletir o que está a acontecer no seu site.
6 dicas para fazer robots.txt para SEO com sucesso
Pronto para implementar um ficheiro robots.txt no seu sítio Web? Aqui estão 6 dicas para o ajudar a fazê-lo com sucesso:
- Certifique-se de que todas as suas páginas importantes são rastreáveis
- Utilize cada user-agent apenas uma vez
- Utilize novas linhas para cada diretiva
- Certifique-se de que utiliza os casos de utilização adequados
- Use o símbolo «*» para indicar uma direção
- Use o símbolo “$” para simplificar a programação
1. Certifique-se de que todas as suas páginas importantes são rastreáveis
Antes de criar o ficheiro robots.txt, é importante identificar as páginas mais importantes do seu Web site. Pretende garantir que essas páginas são rastreadas, para que possam ser classificadas nos resultados de pesquisa.
Antes de criar o ficheiro robots.txt, documente as páginas importantes que pretende permitir que os robots de pesquisa rastreiem. Estas podem incluir páginas como a sua:
- Páginas de produtos
- Página sobre nós
- Páginas informativas
- Publicações no blogue
- Página de contacto
2. Utilizar cada agente de utilizador apenas uma vez
Quando cria o seu ficheiro robots.txt, é importante que cada agente de utilizador seja utilizado apenas uma vez. Fazê-lo desta forma ajuda a manter o seu código limpo e organizado, especialmente se existirem muitas páginas que pretende proibir.
Aqui está um exemplo de robots.txt que mostra a diferença:
User-agent: Googlebot
Disallow: /pageurl
User-agent: Googlebot
Disallow: /loginpage
Agora, imagine que precisava de fazer isto para vários URLs. Ficaria repetitivo e tornaria o seu ficheiro robots.txt difícil de seguir. Em vez disso, é melhor organizá-lo da seguinte forma:
User-agent: Googlebot
Disallow: /pageurl/
Disallow: /loginpage/
Com esta configuração, todos os links não permitidos são organizados sob o user-agent específico. Esta abordagem organizada facilita a procura de linhas que precisa de ajustar, adicionar ou remover para bots específicos.
3. Utilizar novas linhas para cada diretiva
Quando criar o seu ficheiro robots.txt, é crucial que coloque cada diretiva na sua própria linha. Mais uma vez, esta dica facilitará a gestão do seu ficheiro.
Assim, sempre que adicionar um agente de utilizador, este deve estar na sua própria linha com o nome do bot. A linha seguinte deve conter as informações de permissão ou não permissão. Cada linha subsequente de não permissão deve estar sozinha.
Aqui está um exemplo de robots.txt do que não se deve fazer:
User-agent: Googlebot Disallow: /pageurl/ Disallow: /loginpage/
Como pode ver, torna-se mais difícil ler o seu robots.txt e saber o que diz.
Se cometer um erro, por exemplo, será difícil encontrar a linha correcta para corrigir.
Colocar cada diretiva na sua própria linha facilitará a realização de alterações mais tarde.
4. Certifique-se de que utiliza casos de utilização correctos
Se há uma coisa a saber sobre o robots.txt para SEO, é que este ficheiro é sensível a maiúsculas e minúsculas. É necessário garantir que utiliza os casos de utilização adequados, para que funcione corretamente no seu website.
Em primeiro lugar, o seu ficheiro tem de ser rotulado como "robots.txt" nesse caso de utilização.
Em segundo lugar, deve ter em conta quaisquer variações de capitalização dos URLs. Se tem um URL que usa todas as letras maiúsculas, deve introduzi-lo no seu ficheiro robots.txt como tal.
5. Utilizar o símbolo "*" para indicar uma direção
Se tiver vários URLs sob o mesmo endereço que pretende impedir que os bots rastreiem, pode utilizar o símbolo "*", designado por wildcard, para bloquear todos esses URLs de uma só vez.
Por exemplo, digamos que pretende proibir todas as páginas que dizem respeito a pesquisas internas. Em vez de bloquear cada página individualmente, pode simplificar o seu ficheiro.
Em vez de ter este aspeto:
User-agent: *
Disallow: /search/hoodies/
Disallow: /search/red-hoodies/
Disallow: /search/sweaters
Pode utilizar o símbolo "*" para o simplificar:
User-agent: *
Disallow: /search/*
Ao implementar este passo, os bots dos motores de busca são impedidos de rastrear quaisquer URLs na subpasta "search". A utilização do símbolo wildcard é uma forma fácil de não permitir páginas em lotes.
6. Utilizar o "$" para simplificar a codificação
Existem vários truques de codificação que pode utilizar para facilitar a criação do seu ficheiro robots.txt. Um truque é utilizar o símbolo "$" para indicar o fim de um URL.
Se tiver páginas semelhantes que pretenda proibir, pode poupar tempo utilizando o "$" para o aplicar a todos os URLs semelhantes.
Por exemplo, digamos que quer impedir que o Google rastreie os seus vídeos. Veja como esse código pode ficar se você fizer cada um deles:
User-agent: Googlebot
Disallow: /products.3gp
Disallow: /sweaters.3gp
Disallow: /hoodies.3gp
Em vez de os ter todos em linhas separadas, pode utilizar o "$" para não os permitir a todos. Tem o seguinte aspeto:
User-agent: GooglebotDisallow: /*.3gp$
A utilização deste símbolo indica aos rastreadores que as páginas que terminam com ".3gp" não podem ser rastreadas.
Alargar os seus conhecimentos de SEO
Adicionar o robots.txt ao seu sítio Web é crucial para ajudar o Google a rastrear as suas páginas sem o sobrecarregar. É um dos aspectos que o ajudará a fazer SEO de forma eficaz.
Pretende melhorar a SEO do seu site? A nossa equipa de especialistas pode ajudá-lo a implementar estratégias eficazes de robots.txt e a otimizar o seu site para uma melhor indexação. Contacte-nos online hoje para saber como podemos apoiar as suas iniciativas de SEO!
Serviços de SEO que não são de cortar à faca
Obtenha uma estratégia de SEO adaptada ao seu negócio, sector e objectivos de receitas.


Serviços de SEO que não são de cortar à faca
Obtenha uma estratégia de SEO adaptada ao seu negócio, sector e objectivos de receitas.
Escritores
