

Was ist robots.txt?
Robots.txt ist eine Datei, die Suchmaschinen mitteilt, welche Seiten gecrawlt werden sollen und welche zu vermeiden sind. Sie verwendet sowohl "allow"- als auch "disallow"-Anweisungen, um Crawler zu den Seiten zu leiten, die Sie indiziert haben möchten.
Damit Ihre Website in den Suchergebnissen erscheint, muss Google sie crawlen und indexieren. Dieser Vorgang ermöglicht es Google, den Inhalt Ihrer Website zu erkennen, zu verstehen, was auf der Seite steht, und Ihre Seiten in den entsprechenden Suchergebnissen anzuzeigen.
Um Google das Crawlen Ihrer Seiten zu erleichtern, müssen Sie eine robots.txt-Datei verwenden. Auf dieser Seite beantworten wir alle Ihre brennenden Fragen zu robots.txt-Dateien, einschließlich:
- Was ist Robots.txt?
- Robots.txt Datei Anatomie
- Woher stammt die Datei Robots.txt?
- Robots.txt Beispiel
- Warum ist Robots.txt wichtig?
- Wie man eine Robots.txt-Datei erstellt
- Häufige Probleme mit Robots.txt-Dateien
- Wann sollten Sie eine Robots.txt-Datei aktualisieren?
- 6 Tipps, um Robots.txt für SEO erfolgreich durchzuführen
Robots.txt-Datei Anatomie
Erfahren Sie mehr über robots.txt mit dieser anatomischen Aufschlüsselung:
| Komponente | Zweck | Beispiel |
| Benutzer-Agent | Legt fest, für wen die Regel gilt, z. B. alle oder bestimmte Crawler | Benutzer-Agent: Googlebot |
| Nicht zulassen | Legt fest, welche Ordner der User-Agent nicht durchforsten soll | Nicht zulassen: /vertraulich/ |
| Erlauben Sie | Legt fest, welche Ordner der User-Agent innerhalb von nicht zugelassenen Ordnern durchsuchen soll | Gestatten: /vertraulich/öffentlicher-bericht.pdf |
| Kommentare | Legt fest , welche Regeln für die Zuschauer gelten | # Blockiert das Crawlen von /confidential/ durch Googlebot, außer für public-report.pdf |
| Sitemap | Legt fest, wo die XML-Sitemap gespeichert wird | Inhaltsverzeichnis: https://example.com/sitemap.xml |
Woher kommt die robots.txt?
1994 wurde die Datei robots.txt als RobotsNotWanted.txt bezeichnet (als Reaktion auf die Überlastung eines Servers durch einen Web-Crawler), mit dem gemeinsamen Ziel, Webmastern die Möglichkeit zu geben, Crawlern mitzuteilen, was sie nicht crawlen sollen.
Der Name (RobotsNotWanted.txt) hat sich nicht gehalten.
Das Protokoll wurde noch im selben Jahr in robots.txt umbenannt und von den damaligen Suchmaschinen wie AltaVista übernommen. Mehr als zwei Jahrzehnte später formalisierte Google die Verwaltung von robots.txt durch die Internet Engineering Task Force (IETF).
Die IETF konzentriert sich auf die Standardisierung von robots.txt's:
- Benennung, z. B. der Datei "robots.txt".
- Implementierung, z. B. Platzierung der Datei im Stammordner
- Kodierung, z. B. mit UTF-8
- Struktur, wie Gruppen und Regeln
Es ist erwähnenswert, dass Google zwar die Formalisierung der robots.txt-Verwaltung initiiert hat, aber nicht Eigentümer des Protokolls ist. Die IETF ist eine Non-Profit-Organisation (und ein Kind einer anderen Non-Profit-Organisation, der Internet Society), die von Google und seiner Muttergesellschaft Alphabet getrennt ist.
Robots.txt Beispiel
Wie sieht also eine robots.txt-Datei aus? Jede robots.txt-Datei sieht anders aus, je nachdem, was Sie Google zum Crawlen zulassen und was nicht.
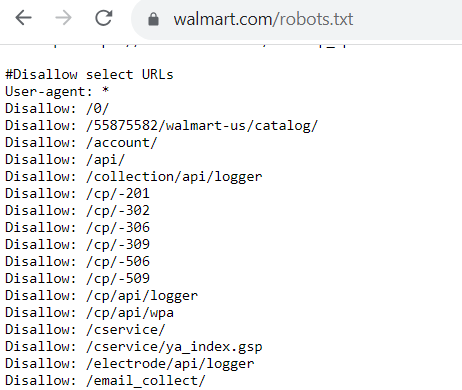
Wenn es Seiten gibt, die Sie Bots zum Crawlen freigeben, sieht der Code wie folgt aus:
User-agent: Googlebot
Allow: /
Der User-Agent ist der Bot, dem Sie das Crawlen Ihrer Website erlauben (oder nicht erlauben). In diesem robots.txt-Beispiel erlauben Sie dem Googlebot, die Seiten Ihrer Website zu crawlen.
Wenn Sie nicht wollen, dass ein Bot die Seiten Ihrer Website durchsucht, sieht der Code wie folgt aus:
User-agent: Bingbot
Disallow: /
In diesem robots.txt-Beispiel zeigt dieser Code an, dass der Bingbot die Seiten einer Website nicht crawlen kann.
Warum ist robots.txt wichtig?
Warum ist robots.txt also wichtig? Warum müssen Sie sich um die Integration dieser Datei in Ihre Website kümmern?
Hier sind einige Gründe, warum die robots.txt für Ihre Suchmaschinenoptimierungsstrategie (SEO) entscheidend ist:
1. Es verhindert, dass Ihre Website überlastet wird
Einer der wichtigsten Gründe für die Implementierung einer robots.txt-Datei besteht darin, zu verhindern, dass Ihre Website mit Crawl-Anfragen überlastet wird.
Mit der robots.txt-Datei können Sie den Crawl-Verkehr auf Ihrer Website so steuern, dass er Ihre Website nicht überfordert und verlangsamt.
Google sendet Crawl-Anfragen, um Seiten auf Ihrer Website zu crawlen und zu indizieren - es kann Dutzende von Anfragen auf einmal senden. Mit der robots.txt-Datei helfen Sie, den Crawl-Verkehr auf Ihrer Website so zu steuern, dass er Ihre Website nicht überfordert und verlangsamt.
Eine langsame Website hat negative Folgen für die Suchmaschinenoptimierung, da Google in den Suchergebnissen schnell ladende Websites anzeigen möchte. Durch die Implementierung der robots.txt-Datei stellen Sie also sicher, dass Google Ihre Website beim Crawlen nicht überlastet und verlangsamt.
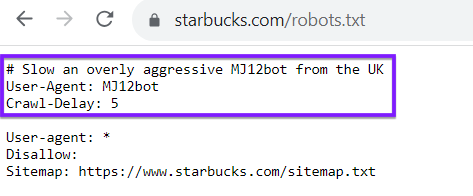
Beachten Sie, dass Ihre robots.txt-Datei nicht nur für Suchmaschinen-Crawler wie Google oder Bing gedacht ist. Sie können Ihre robots.txt-Datei auch verwenden, um Crawler von anderen Websites umzuleiten. Sehen Sie sich zum Beispiel die robots.txt-Datei von Starbucks an, die einen bestimmten Bot aufhält:
2. Es hilft Ihnen, Ihr Crawl-Budget zu optimieren
Jede Website hat ein Crawl-Budget, d. h. die Anzahl der Seiten, die Google innerhalb eines bestimmten Zeitraums crawlt. Wenn Sie mehr Seiten auf Ihrer Website haben, als Sie innerhalb Ihres Crawl-Budgets zulassen können, führt dies dazu, dass die Seiten nicht indiziert werden, was bedeutet, dass sie nicht ranken können.
Ihre robots.txt-Datei kann zwar nicht verhindern, dass Seiten indiziert werden, aber sie kann den Crawlern zeigen, wo sie ihre Zeit verbringen sollen.
Mit robots.txt können Sie Ihr Crawl-Budget optimieren. Sie hilft, die Google-Bots auf die Seiten zu lenken, die Sie indiziert haben möchten. Ihre robots.txt-Datei kann zwar nicht verhindern, dass Seiten indiziert werden, aber sie kann die Crawl-Bots auf die Seiten lenken, die am dringendsten indiziert werden müssen.
3. Es hilft, Crawler daran zu hindern, nicht-öffentliche Seiten zu crawlen
Jedes Unternehmen hat Seiten auf seiner Website, von denen es nicht möchte, dass sie in den Suchergebnissen erscheinen, z. B. Anmeldeseiten und doppelte Seiten. Robots.txt kann dazu beitragen, dass diese Seiten nicht in den Suchergebnissen erscheinen, und blockiert die Seiten vor Crawlern.
Wie man eine robots.txt-Datei erstellt
Gehen Sie folgendermaßen vor, um Ihre robots.txt-Datei zu erstellen:
- Erstellen Sie eine neue Datei in einem Texteditor wie Notepad (Windows) oder TextEdit (Mac)
- Definieren Sie Ihre Regeln, organisiert als Gruppen und Richtlinien
- Erklären Sie anderen Zuschauern, z. B. Teamkollegen, Ihre Regeln mit Kommentaren
- Fügen Sie den Speicherort Ihrer XML-Sitemap am Ende der Datei hinzu
- Speichern Sie Ihre Datei als robots.txt
- Laden Sie Ihre robots.txt-Datei in das Stammverzeichnis Ihrer Website hoch.
- Testen Sie die Regeln Ihrer robots.txt-Datei in Google Search Console und Bing Webmaster Tools
Häufige Probleme mit robots.txt-Dateien
Manchmal treten bei der Verwendung von robots.txt auf Websites Probleme auf. Ein mögliches Problem ist, dass die Datei Google (oder andere Suchmaschinen) daran hindert, Ihre Website überhaupt zu crawlen. Wenn Sie feststellen, dass dies der Fall ist, sollten Sie Ihre robots.txt-Datei aktualisieren, um das Problem zu beheben.
Ein weiteres mögliches Problem besteht darin, dass sich irgendwo auf Ihrer Website sensible oder private Daten befinden (die entweder für Ihr Unternehmen oder für Ihre Kunden privat sind), die von der robots.txt-Datei nicht gesperrt werden, so dass Google diese Daten ungehindert crawlen kann. Das ist ein schwerwiegender Verstoß, also müssen Sie sicherstellen, dass Sie diese Daten vor Crawlern sperren.
Wann sollten Sie eine robots.txt-Datei aktualisieren?
Auch nachdem Sie eine robots.txt-Datei erstellt haben, müssen Sie sie wahrscheinlich irgendwann aktualisieren. Aber wann genau müssen Sie das tun?
Im Folgenden finden Sie einige Zeitpunkte, zu denen Sie Ihre robots.txt-Datei aktualisieren sollten:
- Wenn Sie auf ein neues Content-Management-System (CMS) umsteigen
- Wenn Sie das Crawling Ihrer Website durch Google verbessern wollen
- Wenn Sie einen neuen Bereich oder eine neue Subdomain zu Ihrer Website hinzufügen
- Wenn Sie auf eine völlig neue Website wechseln
Für alle diese Änderungen müssen Sie Ihre robots.txt-Datei bearbeiten, damit sie die Vorgänge auf Ihrer Website widerspiegelt.
6 Tipps zur erfolgreichen Durchführung von robots.txt für SEO
Sind Sie bereit, eine robots.txt-Datei auf Ihrer Website zu implementieren? Hier sind 6 Tipps, die Ihnen helfen, dies erfolgreich zu tun:
- Make Sure All Your Important Pages Are Crawlable
- Only Use Each User-agent Once
- Use New Lines for Each Directive
- Make Sure You Use Proper Use Cases
- Use the “*” Symbol to Give Direction
- Use the “$” to Simplify Coding
1. Stellen Sie sicher, dass alle Ihre wichtigen Seiten crawlbar sind
Bevor Sie Ihre robots.txt-Datei erstellen, ist es wichtig, die wichtigsten Seiten Ihrer Website zu identifizieren. Sie möchten sicherstellen, dass diese Seiten gecrawlt werden, damit sie in den Suchergebnissen erscheinen können.
Bevor Sie Ihre robots.txt-Datei erstellen, dokumentieren Sie die wichtigen Seiten, die Sie den Suchrobotern zum Crawlen überlassen wollen. Dazu können Seiten wie Ihre:
- Produkt-Seiten
- Über uns Seite
- Informationsseiten
- Blog-Beiträge
- Kontakt Seite
2. Verwenden Sie jeden Benutzer-Agenten nur einmal
Wenn Sie Ihre robots.txt-Datei erstellen, ist es wichtig, dass jeder Benutzer-Agent nur einmal verwendet wird. Auf diese Weise bleibt Ihr Code sauber und übersichtlich, vor allem, wenn Sie mehrere Seiten nicht zulassen möchten.
Hier ist ein robots.txt-Beispiel, das den Unterschied zeigt:
User-agent: Googlebot
Disallow: /pageurl
User-agent: Googlebot
Disallow: /loginpage
Stellen Sie sich nun vor, Sie müssten dies für mehrere URLs tun. Das würde sich wiederholen und Ihre robots.txt-Datei unübersichtlich machen. Stattdessen ist es am besten, sie wie folgt zu organisieren:
User-agent: Googlebot
Disallow: /pageurl/
Disallow: /loginpage/
Bei dieser Einrichtung werden alle nicht zugelassenen Links unter dem jeweiligen User-Agent organisiert. Dieser organisierte Ansatz macht es einfacher für Sie, Zeilen zu finden, die Sie für bestimmte Bots anpassen, hinzufügen oder entfernen müssen.
3. Verwenden Sie neue Zeilen für jede Richtlinie
Wenn Sie Ihre robots.txt-Datei erstellen, ist es wichtig, dass Sie jede Richtlinie in eine eigene Zeile setzen. Auch dieser Tipp wird Ihnen die Verwaltung Ihrer Datei erleichtern.
Wenn Sie also einen Benutzeragenten hinzufügen, sollte er in einer eigenen Zeile mit dem Bot-Namen stehen. Die nächste Zeile sollte die Informationen zum Verbieten oder Zulassen enthalten. Jede nachfolgende Disallow-Zeile sollte in einer eigenen Zeile stehen.
Das folgende robots.txt-Beispiel zeigt, was man nicht tun sollte:
User-agent: Googlebot Disallow: /pageurl/ Disallow: /loginpage/
Wie Sie sehen können, wird es dadurch schwieriger, Ihre robots.txt zu lesen und zu wissen, was darin steht.
Wenn Sie z. B. einen Fehler machen, ist es schwierig, die richtige Zeile zu finden, um sie zu korrigieren.
Wenn Sie jede Richtlinie in eine eigene Zeile setzen, können Sie später leichter Änderungen vornehmen.
4. Stellen Sie sicher, dass Sie die richtigen Anwendungsfälle verwenden
Wenn es eine Sache gibt, die man über die robots.txt für SEO wissen muss, dann ist es, dass diese Datei Groß- und Kleinschreibung unterscheidet. Sie müssen sicherstellen, dass Sie die richtigen Anwendungsfälle verwenden, damit sie auf Ihrer Website korrekt funktioniert.
Zunächst muss Ihre Datei in diesem Fall als "robots.txt" bezeichnet werden.
Zweitens müssen Sie alle Variationen der Großschreibung von URLs berücksichtigen. Wenn Sie eine URL haben, die alle Großbuchstaben verwendet, müssen Sie sie als solche in Ihre robots.txt-Datei eingeben.
5. Verwenden Sie das Symbol "*", um die Richtung anzugeben.
Wenn Sie zahlreiche URLs unter derselben Adresse haben, die Sie für Bots sperren wollen, können Sie das Symbol "*", den so genannten Platzhalter, verwenden, um alle diese URLs auf einmal zu sperren.
Nehmen wir zum Beispiel an, Sie möchten alle Seiten sperren, die sich auf interne Suchen beziehen. Anstatt jede Seite einzeln zu sperren, können Sie Ihre Datei vereinfachen.
Stattdessen sollte es so aussehen:
User-agent: *
Disallow: /search/hoodies/
Disallow: /search/red-hoodies/
Disallow: /search/sweaters
Zur Vereinfachung können Sie das "*"-Symbol verwenden:
User-agent: *
Disallow: /search/*
Durch diesen Schritt werden Suchmaschinen-Bots daran gehindert, alle URLs unter dem Unterordner "search" zu crawlen. Die Verwendung des Platzhaltersymbols ist eine einfache Methode, um Seiten stapelweise zu sperren.
6. Verwenden Sie das "$", um die Codierung zu vereinfachen
Es gibt zahlreiche Codierungstricks, mit denen Sie die Erstellung Ihrer robots.txt-Datei erleichtern können. Ein Trick besteht darin, das "$"-Symbol zu verwenden, um das Ende einer URL zu kennzeichnen.
Wenn Sie ähnliche Seiten haben, die Sie nicht zulassen wollen, können Sie sich Zeit sparen, indem Sie das "$" verwenden, um es auf alle ähnlichen URLs anzuwenden.
Nehmen wir an, Sie möchten verhindern, dass Google Ihre Videos crawlt. So könnte der Code aussehen, wenn Sie jeden einzelnen Schritt ausführen:
User-agent: Googlebot
Disallow: /products.3gp
Disallow: /sweaters.3gp
Disallow: /hoodies.3gp
Anstatt sie alle in separaten Zeilen zu haben, können Sie das "$" verwenden, um sie alle zu verbieten. Das sieht dann so aus:
User-agent: GooglebotDisallow: /*.3gp$
Die Verwendung dieses Symbols zeigt den Crawlern an, dass alle Seiten, die mit ".3gp" enden, nicht gecrawlt werden können.
Erweitern Sie Ihr SEO-Wissen
Das Hinzufügen von robots.txt zu Ihrer Website ist wichtig, damit Google Ihre Seiten crawlen kann, ohne sie zu überladen. Es ist einer der Aspekte, die Ihnen helfen, SEO effektiv zu betreiben.
Möchten Sie die SEO Ihrer Website verbessern? Unser Expertenteam kann Ihnen helfen, effektive robots.txt-Strategien zu implementieren und Ihre Website für eine bessere Indexierung zu optimieren. Kontaktieren Sie uns noch heute online, um zu erfahren, wie wir Ihre SEO-Initiativen unterstützen können!
SEO-Dienstleistungen, die nicht aus einem Guss sind
Sie erhalten eine SEO-Strategie, die auf Ihr Unternehmen, Ihre Branche und Ihre Umsatzziele zugeschnitten ist.


SEO-Dienstleistungen, die nicht aus einem Guss sind
Sie erhalten eine SEO-Strategie, die auf Ihr Unternehmen, Ihre Branche und Ihre Umsatzziele zugeschnitten ist.
Schriftsteller
