
What is website crawling?
Website crawling is the process of search engine bots crawling the Internet to find and index pages for search engines. Search engines rely on bots, or web crawlers, to index pages to deliver relevant websites in the search results to users.
Website crawling allows search engines to find and deliver relevant content to searchers. This website crawling 101 guide covers everything you need to know about site crawling and web crawlers, so let’s get started!
- What is Website Crawling?
- Why is Website Crawling Important?
- How Does Website Crawling Work?
- How to Optimize for Website Crawling
- 3 Reasons Why Your Site Isn’t Getting Crawled (and How to Fix It!)
Why is website crawling important?
Without website crawling, search engines like Google wouldn’t know your website exists, and therefore, your pages wouldn’t rank in search engine results pages (SERPs). Obviously then, making sure your content is crawlable is extremely important if you want it to rank well.
How does website crawling work?
We can break down the process of how website crawling works into these steps:
- Search engine crawlers scour web pages on the Internet: Search engine bots crawl websites by passing between links on pages to identify and collect data on web pages.
- Search engine crawlers collect data about web pages: As search engine crawlers find different web pages on the Internet, they collect information about those pages, such as their titles, meta descriptions, copy, and more.
- Search engine crawlers send data to search engines: After a search engine crawler collects information about a web page, they send that data to search engines.
- Search engines index the web page: Once a search engine receives data about a web page from a crawler, it will store and categorize the data in its database, also known as indexing.
- Search engines rank the web page: When a user searches for something using a search engine, that search engine will dig through the web pages in its database to return the best websites for the query in the search results.
Website crawling is extremely important for search engines, users, and businesses alike. For search engines, without crawling, they wouldn’t be able to deliver the information and answers users need.
And for businesses, if your website isn’t crawled and search engines don’t index your pages, your site won’t rank in the search results, and users won’t be able to discover your business.
It’s simple.
If Google can’t find your content, how would Google know to rank your website?
Now that you know what a web crawler is and how website crawling works, let’s dive into the next chapter of our website crawling 101 guide — how to optimize for website crawling.
How to optimize for website crawling
You must make sure your site can be crawled and indexed by search engines in order to rank in the search results so that users can discover your business.
But how can you ensure that search engines crawl your site?
Here’s how to optimize for website crawling to ensure search engines can index and rank your pages:
- Make sure your server response is as fast as possible
- Improve your page load speed
- Add more internal links throughout your site
- Submit your sitemap to Google
- Remove low-quality and duplicate content
- Find and fix any broken links
- Inform search engines how they should crawl your site with robots.txt files
- Check your redirects
1. Make sure your server response is fast
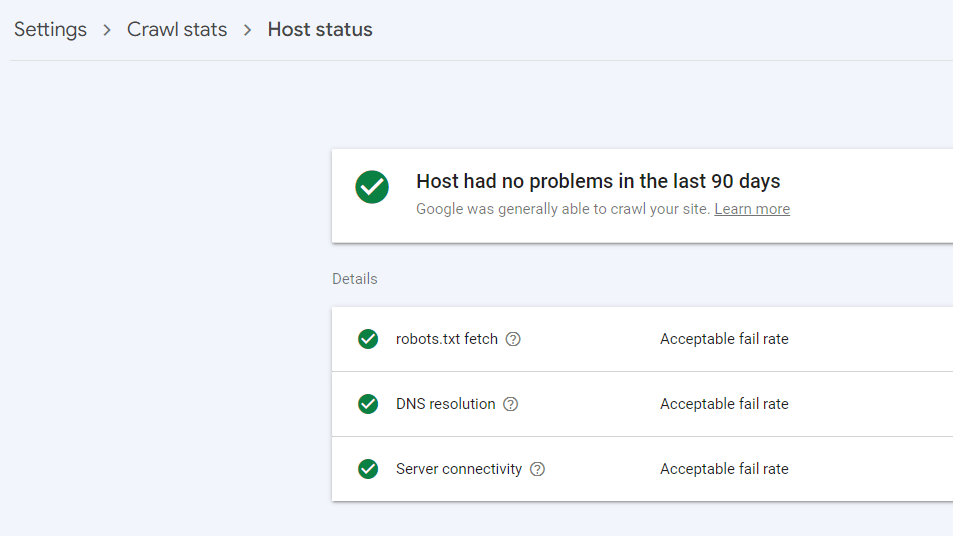
Crawling can take a toll on your website. That’s why having a high-performing server is important. Your server should be able to handle a lot of crawling from search engines without wreaking any havoc on your server, like lowering its response time.
Use Google Search Console to easily check your server response time with the Site Host status report. You’ll want to aim for a response time of less than 300 milliseconds.
2. Improve your page load speed
Not only does your page load speed impact users, but it can also impact website crawlers. Web crawlers usually stick to what is known as a crawl budget — the number of pages search engines will crawl on a website within a certain timeframe.
Web crawlers can’t wait around all day for your pages to load so they can crawl them. Improve your page load speed so that everything loads as fast as possible to ensure that all of your pages can be crawled successfully. You can check your site speed by using Google’s PageSpeed Insights tool.
Pro tips
- Our free SEO Checker can analyze your page speed, list ways to improve it if needed, and even highlight specific files you can compress to speed up your site. Enter your website to get your custom report.
- You can also use Google’s Page Speed Insights tool to view your site’s current load time. Open up your Core Web Vitals report in Google Search Console to see exactly what’s slowing down your load speed and take steps to rectify it.
3. Add more internal links throughout your site
We mentioned before that web crawlers crawl your website by passing between links on your pages. A lack of internal links and disorganized structure makes it difficult for crawlers to accurately crawl and index your pages.
Improving your internal linking strategy is one of the best ways to optimize for website crawling. Add internal links throughout your content and website to other pages on your site to strengthen your internal linking strategy.
Pro tips
- Ensure your home page links to other important pages on your site and that those pages also link to other pages on your website. The sooner the crawler can find your most important content, the better.
- Add links in the text of your content to relevant pages across your site. Try branching out to other areas of your site too so the crawler can find those deeper pages.
- Consider adding navigational links at the bottom of your blog posts and articles to recommend further reading for users and help search engines crawl more pages on your site.
4. Submit your sitemap to Google
Another top tip for how to optimize for website crawling is to take the initiative by submitting your sitemap to Google.
It’s no good sitting around and waiting for Google’s search engine bots to crawl your site when they feel like it when you’re ready now.

Instead, give Google the map to find everything you want it to crawl within Google Search Console.
Submit your sitemap to Google to provide it with an entire roadmap of all the pages on your site so Google can index them right away.
Pro tip
You can submit your sitemap to Google through Google Search Console. Just click on “Sitemaps” on the menu under “Indexing.” Then, you can upload your sitemap and select submit!
5. Remove low-quality and duplicate content
A search engine’s main goal is to provide users with a great experience when they search online, and that involves showing them valuable content that answers their questions and provides them with helpful information.
Each page a crawler finds is another page it doesn’t get to see in a given time period. So if you have lots of low value pages on your site wasting the crawler’s time, the longer it’ll take for it to find the good stuff.
If search engines like Google don’t think your content is helpful or valuable, they may not index your pages. Duplicate content can also confuse search engine crawlers and make them unsure of which page to index.
It’s best practice to find these low-quality and duplicate pages and remove them to optimize your site for website crawling.
Pro tip
Review Google’s helpful content tips to ensure you produce valuable content for users. You can also identify duplicate content through your Crawl Stats report in Google Search Console by looking for duplicate tags.
6. Find and fix any broken links
Broken links aren’t good for search engine crawlers or your website visitors, so finding and fixing them as quickly as possible is always a good idea.
You should also consider regularly checking your website for broken links to ensure you can remove them when they pop up.
If you have a substantial amount of broken internal links or redirects, it creates extra hoops for the crawler to jump through. This creates a lot of wasted crawl budget.
Pro Tip
Use tools like Google Search Console or Screaming Frog to easily find 404 errors and either redirect those links, update them, or remove them completely.
7. Tell search engines how they should crawl your site with robots.txt files
A Robots.txt file is a plain text file in your site’s root directly and is responsible for managing traffic from bots and preventing your website from being overrun with requests. Google usually obey the robots.txt file and crawl or not crawl your site based on the rules you define there.
Robots.txt files help you tell search engine crawlers how you want them to crawl your website. For example, you can tell Google not to crawl pages like shopping carts or directories.
Pro tip
Robots.txt files can be tricky, and if you’re not careful, you could cause search engine crawlers to not crawl important pages on your site. We have seen businesses accidentally block Google entirely, so be careful and double check your robots.txt file!
8. Check your redirects
Redirects direct users from one page on your site to a newer or more relevant one and are quite common for most websites to use.
However, if you aren’t careful, you could make a few mistakes that cause search engine crawlers to become confused and unable to crawl your pages successfully, hurting your rankings in the search results.
For example, it’s important to make sure that your redirects direct users (and crawlers) to a relevant page and be wary of creating a redirecting loop — where you direct users to one page, which redirects them to another one, and so on.
Pro tip
Use a tool like Screaming Frog to check your site’s redirects, ensure they are in tip-top shape, and identify and remove any redirect loops.
3 reasons why your site isn’t getting crawled (and how to fix it!)
Is your website not getting crawled or indexed by search engines? Troubleshoot some common reasons why your site isn’t crawled and how to fix the issue below!
1. Your page isn’t discoverable
Sometimes, search engines can’t crawl your page or site because they simply can’t find it! Search engines may not be able to discover your website if you have one or more of the following issues:
- Your page doesn’t have any internal links on other pages of your site
- Your page wasn’t listed in the sitemap you submitted to Google
- Your website is too slow to load
- You have the page noindexed via meta tags or the robots.txt file
How to fix it
- Add internal links to your page from other pages on your website
- Add your page to your sitemap and re-submit to Google
- Optimize your page load speed by using Google Search Console’s Core Web Vitals report
2. Your server encountered an error
Next on our list of reasons why your website isn’t getting crawled is that your server encountered an error.
It’s essential that your server can handle the stress of search engine bots crawling your site. If your server’s response time is too slow or is subject to consistent errors, it could prevent search engine crawlers from crawling and indexing your pages.
How to fix it
View server errors and 5xx errors in Google Search Console’s indexing report or by using a tool like Screaming Frog to quickly identify errors.
You can also try the following methods:
- Disable faulty WordPress plugins
- Undo recent server updates
- Contact your hosting provider
3. Your crawl budget is low
We mentioned above that a crawl budget refers to the number of pages that search engine bots will crawl within a given time period.
If your website is large with lots of URLs, your crawl budget may be too low — meaning that web crawlers take longer to crawl all of the pages on your website.
How to fix it
While the search engine typically sets crawl budgets, there are a few things you can do to impact it so that search engines can crawl and index all of your pages, such as:
- Fixing 404s and removing excessive redirects or redirect chains
- Improving your server response time and page load speed
- Removing non-canonical URLs
Optimize your website with SEO.com
Ready to optimize your website for better accessibility and SEO? Our professional services can help you implement best practices for alt text and boost your overall search performance. Contact us online today to learn how we can elevate your SEO strategy!
SEO Services That Aren’t Cookie Cutter
Get an SEO strategy that’s tailored for your business, industry, and revenue goals.


SEO Services That Aren’t Cookie Cutter
Get an SEO strategy that’s tailored for your business, industry, and revenue goals.
Writers
